The context doesn't remember itself
Using a workspace and an agent to replace the notes you never write
Losing project context is more common than it seems. Sometimes it happens because the project grows and too many people are involved. Other times because you are working on something alone, you leave it behind, and when you come back weeks later you no longer remember where you left off or what was still pending. There is one particular case I am living firsthand.
I am a part-time PhD student. Most of my time goes to my main job as an engineer, and the rest to my thesis. Even though the topics are related, the context switch is total: when I finally get some time to sit down and do research, the first few minutes are spent remembering where I left things, what state the code was in, or whether I actually reviewed all the points from the last meeting with my supervisor. I used to take notes in Obsidian to soften that, but it requires a level of commitment I did not always maintain. If I left a feature half done or thought I would continue the next day, I would not document it. And of course, the next day sometimes came three weeks later.
Along the way through the PhD, AI arrived in a way that could be folded into my workflow, and some of the project documentation started being handled by an agent. The lightbulb went on when I read this from Andrej Karpathy. In practice it was hard to avoid hearing about it anyway, because although I do not use Twitter, I came across it this way.
I spent some time thinking about it and I was clear that, given the way I manage my Obsidian vault, it was not something I needed right away. But it gave me an idea that I could actually apply.
What if we follow the same strategy and let an LLM orchestrate the administrative work of the PhD?
How I’m using it
The implementation came about rather naturally: since the development of the code project and the papers was already happening in VS Code, I could use Workspaces to unify everything (code, papers, documentation, and the Obsidian vault) under the same umbrella. Step 1, done.
The first task I asked the agent to do, before generating the plan, was a full analysis of the workspace: application architecture, vault file structure, and content. The point was not only to make sure it knew what we were talking about, but also to have it suggest changes to the documentation structure or add things that would make future work easier.
The next step was to generate an AGENTS.md so the agent would know what to do every time the workspace is opened and a new session starts. In that plan I pointed it to the files that provide context about the current state of the PhD, the architecture of the code project, the location of the papers, the calendar and delivery status, and so on. To avoid overwhelming the context, the AGENTS file points to other files depending on what the agent needs: architecture, calendar, planning, paper status, research questions, conclusions and analysis, session logs.
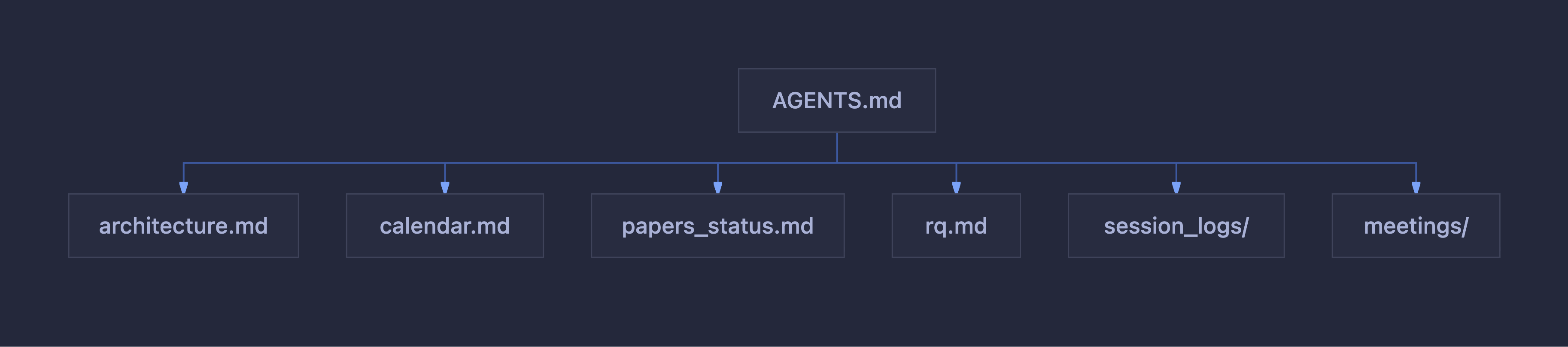
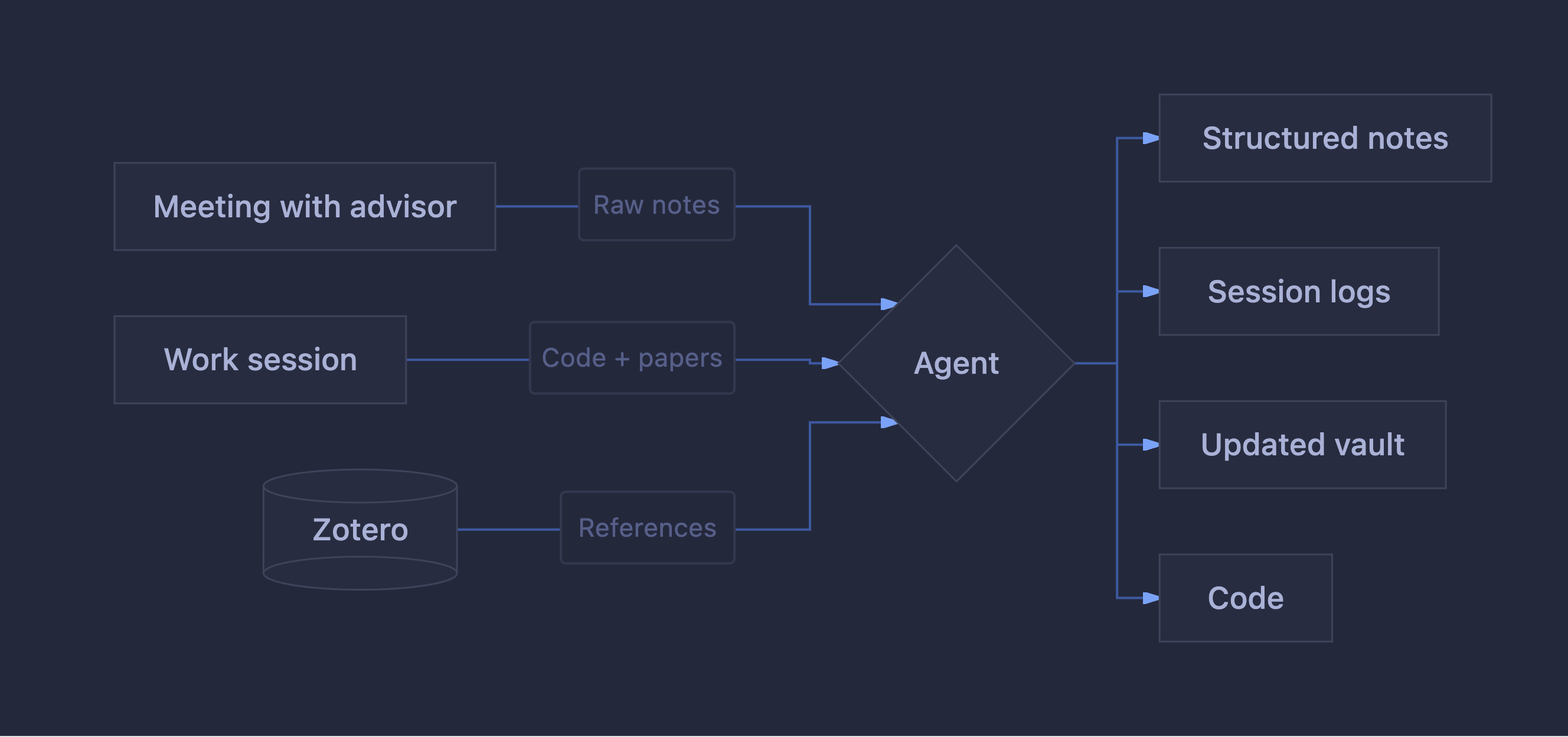
As part of the documentation, I also specified that after each work session the agent should create a file documenting what was done, the changes that were made, and update all documents related to those changes, so the vault stays up to date.
That leaves us with roughly two modes of operation:
After a meeting with my supervisor: I quickly pass in the notes I took during the meeting. They are usually a bit of a mess, so I have been surprised by the amount of information and the relationships it can derive from the workspace content. In this process it generates meeting notes with the comments made, the status of development or papers, next steps, and, at the end, the raw notes. The next step will probably be recording the meetings and passing in the transcript, but I will leave that for later.
Work session: I ask the agent for a summary of the last session and the last meeting, and then decide what I should work on. The downside of this way of working is that, little by little, you keep generating more and more context, so if the session is very long it is sometimes necessary to ask the agent to summarize it so I can pick it up in another session and “clear the context” (and also save tokens).
Bonus: Zotero integration
One very interesting thing about Zotero is that it provides a local API, so you can connect to the open instance and query data directly. The API also allows access to PDF documents, so I came up with creating a skill that lets me search for references in Zotero and add them to the paper in BibTeX, or simply ask questions and have it tell me which papers talk about a specific topic or whether that information already exists in Zotero.
It took me some time to make this change in mindset, but the result is that I no longer work in silos: I do not work on a paper in Overleaf, or on a feature, or on documentation. I work in the workspace all the time, and the agent documents and collaborates throughout the whole process.
There is something curious to me about this. The few references I have with the scientific community, conferences, meetings, conversations with other researchers, often convey a very specific perception of AI: skepticism, distance, sometimes active rejection, and sometimes pride in not using it or even knowing it. I understand part of that stance: there are legitimate questions about authorship, rigor, fit within the scientific process, and what it means for a model to “help” in a research project. But assuming that using AI necessarily means it thinks for you seems to me like a generalization that does not hold up for very long, and even less so from a community that in theory embraces questioning as a method. In the example in this article, the AI handles the administrative and operational side that otherwise simply does not get done. Nobody questions using a spreadsheet to track an experiment. This does not seem that different to me.