El contexto no se recuerda solo
Usar un workspace y un agente para sustituir las notas que nunca escribes
Perder el contexto de un proyecto es más común de lo que parece. A veces porque el proyecto crece y hay demasiadas personas involucradas. Otras porque trabajas en algo solo, lo dejas, y cuando lo retomas semanas después ya no recuerdas dónde lo dejaste ni qué tenías pendiente. Hay un caso particular que estoy viviendo en primera persona.
Soy estudiante de doctorado a tiempo parcial. La mayor parte de mi tiempo lo empleo en mi trabajo principal como ingeniero, y el resto lo dedico a la tesis. Aunque los temas están relacionados, el cambio de contexto es total: cuando por fin consigo hueco para sentarme a investigar, los primeros minutos los paso recordando dónde lo dejé, en qué estado quedó el código, o si realmente revisé todos los puntos de la última reunión con el director. Tomaba notas en Obsidian para mitigarlo, pero exige un compromiso que no siempre cumplía. Si dejaba una funcionalidad a medias o pensaba que iba a seguir al día siguiente, no documentaba. Y claro, el día siguiente a veces llegaba tres semanas después.
Por supuesto que por el camino del doctorado llegó la IA de un modo que podía incorporarlo en mi flujo de trabajo, y cierta documentación del proyecto de código la comenzó a hacer un agente. La bombilla se encendió cuando leí esto de Andrej Karpathy. En realidad ha sido difícil no leer sobre ello, ya que aunque no tengo Twitter, me llegó así.
La cosa es que estuve dándole vueltas y tenía claro que, por mi modo de gestionar mi vault en Obsidian, no era algo que necesitara de momento, pero me dio una idea que sí que podía aplicar.
¿Y si seguimos la misma estrategia y dejamos que un LLM orqueste las cuestiones administrativas del doctorado?
La implementación surgió de modo más o menos natural: como el desarrollo del proyecto de código y los papers se estaba realizando en VSCode, podía hacer uso de los Workspaces y de este modo unificar todo (código, papers, documentación y el vault de Obsidian) bajo un mismo paraguas. Paso 1, realizado.
La primera tarea que realicé con el agente fue, previo a la generación del plan, que realizara un análisis completo del workspace: arquitectura de la aplicación, estructura de ficheros del vault y contenido. Todo ello no solo para que supiera “de qué estamos hablando”, sino para que propusiera cambios en la estructura de la documentación o añadiera cosas para facilitar el trabajo futuro.
Lo siguiente fue generar un AGENTS.md para que el agente sepa qué hacer cada vez que se abre el workspace y se crea una nueva sesión. En dicho plan le indiqué dónde se ubicaban los ficheros que le daban contexto sobre el estado actual del doctorado, arquitectura del proyecto de código, ubicación de los papers, calendario y estado de las entregas, etc. Para no saturar el contexto el AGENTS hace referencia a otros ficheros en función de la necesidad que tenga el agente: arquitectura, calendario, planificación, estado de los papers, research questions, conclusiones y análisis, logs de sesiones.
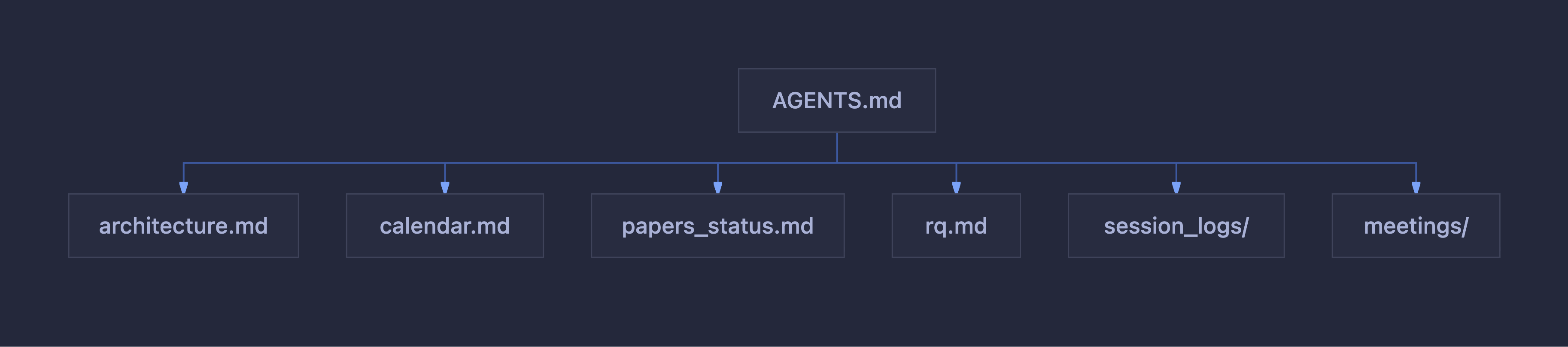
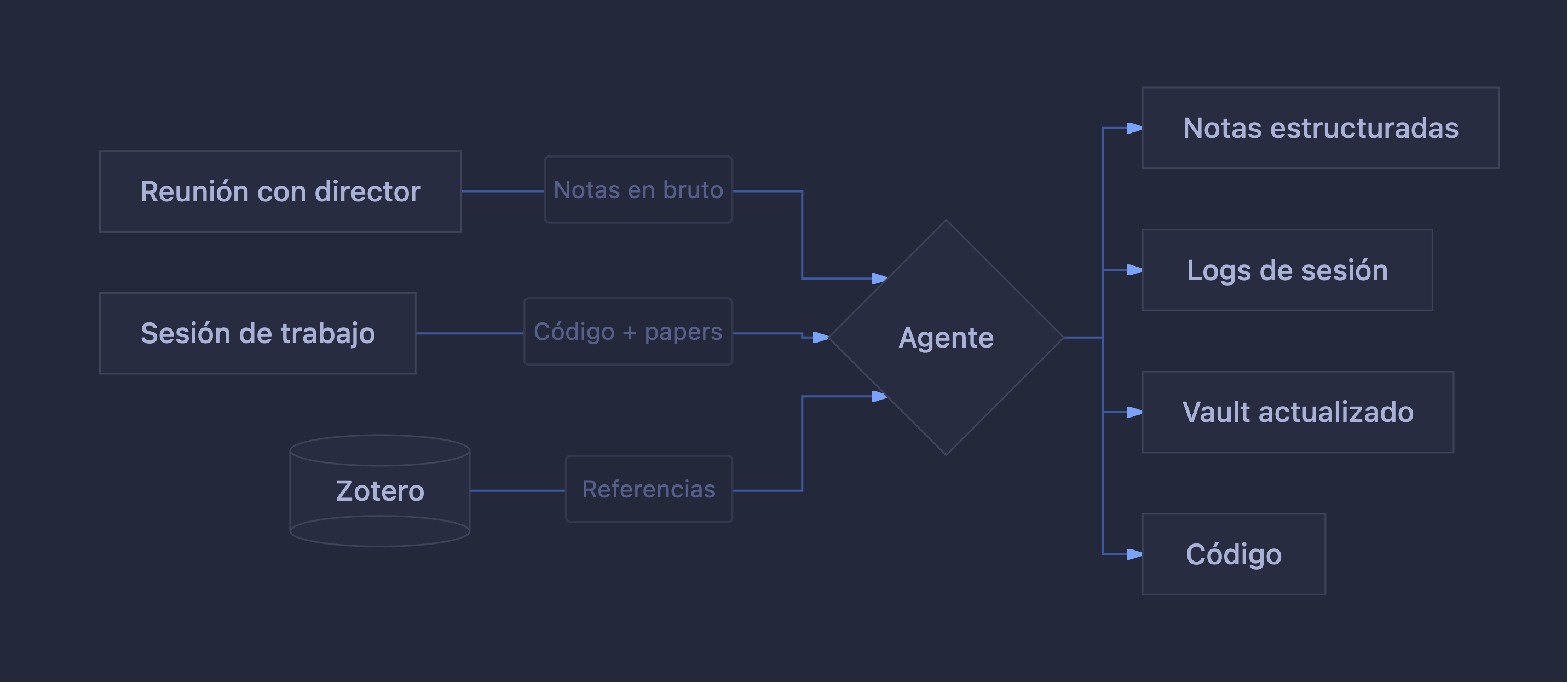
Como parte de la documentación también indiqué que tras cada sesión de trabajo, el agente debía crear un fichero documentando lo realizado, los cambios hechos, y actualizar todos los documentos relativos a esos cambios, para tener siempre el vault al día.
Tras esto nos quedan más o menos dos operativas:
Tras reunión con el director: le paso las notas que he tomado rápidamente en la reunión. Normalmente suelen ser un poco desastrosas, por lo que me he quedado sorprendido con la cantidad de información y las relaciones que puede hacer con el contenido del workspace. En este proceso genera unas notas de reunión con los comentarios realizados, estado del desarrollo o papers, próximas acciones y, al final, las notas en bruto. El siguiente paso seguramente sea grabar las reuniones y pasar la transcripción, pero eso lo dejo para más adelante.
Sesión de trabajo: le pido al agente que me haga un resumen de la última sesión y de la última reunión, y decido sobre qué trabajar. Este modo de trabajo tiene el problema de que poco a poco vas generando cada vez más contexto, por lo que si la sesión es muy larga, a veces es necesario pedirle al agente que realice un resumen para retomarla en otra sesión y “limpiar el contexto” (y también ahorrar tokens).
Bonus: integración con Zotero
Una cosa muy interesante que tiene Zotero es que dispone de una API local, por lo que puedes conectarte a la instancia que tienes abierta y consultar datos directamente. La API también permite acceder a los documentos PDF, por lo que se me ocurrió crear un skill que permita buscar referencias en Zotero y añadirlas en BibTeX al paper, o simplemente hacer preguntas y que me responda qué papers hablan de un tema concreto o si existe esa información en Zotero.
Me ha llevado un tiempo este cambio de mentalidad, pero el resultado es que ya no trabajo en silos: no trabajo en un paper en Overleaf, ni en una feature, ni en documentación. Trabajo en el workspace todo el tiempo, y el agente documenta y colabora en todo el proceso.
Hay algo que me resulta curioso al respecto. Las pocas referencias que tengo con la comunidad científica, congresos, reuniones, conversaciones con otros investigadores, transmiten con frecuencia una percepción muy concreta sobre la IA: escepticismo, distancia, a veces rechazo activo, y a veces orgullo de no usarla ni conocerla. Entiendo parte de esa postura: hay preguntas legítimas sobre autoría, sobre rigor, sobre el encaje en el proceso científico y sobre qué significa que un modelo “ayude” en una investigación. Pero asumir que usar IA implica necesariamente que piense por ti me parece una generalización que no resiste mucho análisis, y menos desde una comunidad que en teoría abraza el cuestionamiento como método. En el ejemplo de este artículo la IA gestiona la parte administrativa y operativa que de otro modo simplemente no haces. Nadie cuestiona usar una hoja de cálculo para llevar el seguimiento de un experimento. Esto no me parece tan diferente.